Review of YouTube, Meta, and TikTok researcher access.

In lieu of the enforcement of the Digital Services Act in the EU, which would supposedly make data access easier for researchers, this blog post reviews current data access programs for the academics. What kind of data do platforms allow to access and by whom? Read a detailed description of the programs by the YouTube, Meta and TikTok as of May 2023
The Twitter Academic API as we know it is dead. It was a great program for academic research that lasted roughly two years. When I was writing my PhD on Twitter discussions around news in Russian authoritarianism (2019), the sales representative of Twitter quoted a 2000 USD cost for the historical data that I needed. As a postgraduate student I could not pay for it. Only three years later, in the spring of 2022, it was already possible to gather historical data from 2012 till 2022 of 10 million tweets through the Twitter academic access for the project “Imaginaries of AI” at our Platform Governance, Media and Technology Lab (PGMT) at the University of Bremen.
Now, in May 2023, the Academic Access page leads to an offer to buy a “Basic” Tier Twitter API access for 100 USD per month, which would let you gather 10 000 tweets per month, a bare minimum for teaching how to handle social media data analysis. Other than that, enterprise access, which academics are now also offered to subscribe to, offers access for a minimum of 42 000 USD per month. If you try to use the “more resources for researchers” button on Twitter website, you would now see the picture of a poodle and a byline: “Nothing to see here. Looks like this page doesn’t exist. Here’s a picture of a poodle sitting in a chair for your trouble”
There is hope that European Union’s Digital Services Act and its new data access regime for researchers will change that in 2024, forcing Twitter even under Musk’s leadership to offer something more substantial than a picture of a poodle for academia.
At the moment, however, there are three social media platforms that are offering researcher access to their API. The TikTok program for researchers was made available in February 2023 but to this date it is still limited only to US-based researchers. The YouTube research program is available since 2022, and Meta’s CrowdTangle tool and API for the researchers has been functioning since 2019 but only allows research on limited topics.
It is important to note that none of those programs allows exploring moderated data that had been taken down. Moreover, YouTube and TikTok make provisions for data sets to be mandatorily updated for the deleted data not to be present in a dataset. Which means that even if a researcher has the data deleted by moderation or otherwise in their dataset, they have to delete it, too, once it is deleted from the platform. In practice, it makes content moderation research impossible. CrowdTangle does not show the deleted data at all.
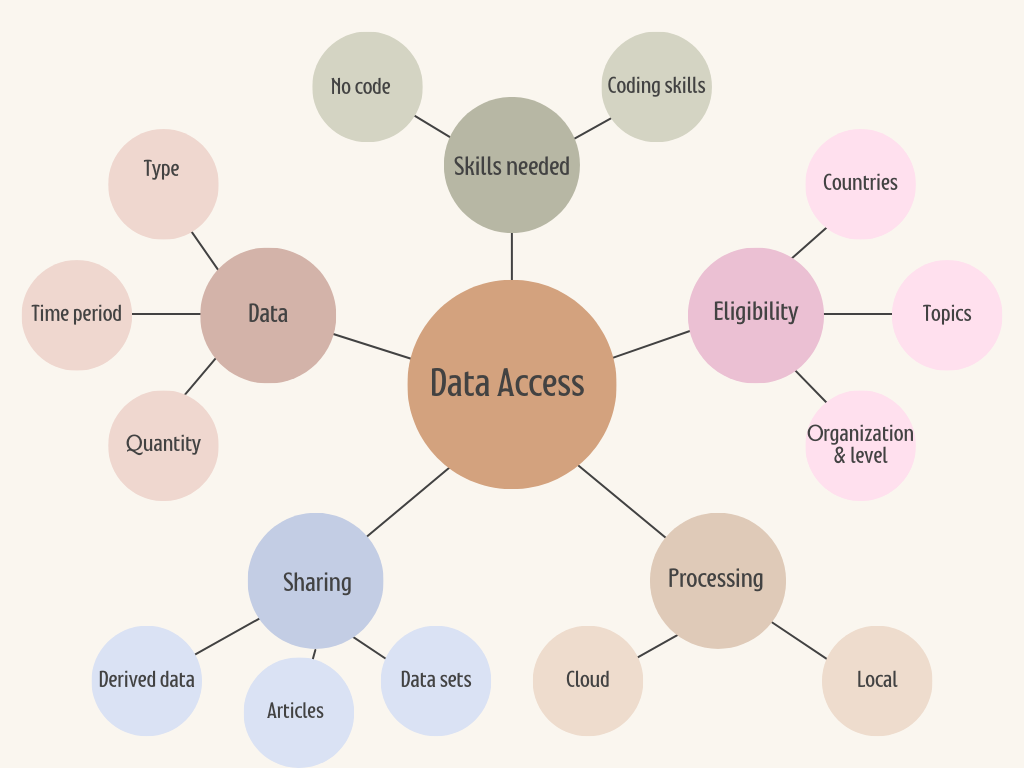
We have explored the three currently available social media platforms research programs according to the following scheme:
YouTube researcher program
Who is eligible
By application, researchers from accredited academic institutions, from the following countries: Argentina, Australia, Austria, Belgium, Brazil, Bulgaria, Canada, Chile, Colombia, Cyprus, Czech Republic, Denmark, Egypt, Estonia, Finland, France, Germany, Ghana, Greece, Hungary, India, Indonesia, Ireland, Israel, Italy, Japan, Kenya, Korea, Latvia, Lithuania, Luxembourg, Malaysia, Malta, Mexico, Morocco, Netherlands, New Zealand, Nigeria, Norway, Oman, Philippines, Poland, Portugal, Qatar, Romania, Saudi Arabia, Senegal, Singapore, Slovakia, South Africa, Spain, Sweden, Switzerland, Taiwan, Thailand, Tunisia, United Arab Emirates, United Kingdom, United States, Vietnam.
Topics:
wide range of topics, by application
Sources
What is available: access to standard YouTube API
Which Data: Meta-data of channels and videos retrieved from YouTube API v.3. Here is an overview of what data is currently available through YouTube API
How Many: By application, downloading quota can be increased (standard developers quota is 10 000 requests per day, there is no limit officially stated in research program, thus, differs according to application)
Which time period: according to application, one research project
Is the documentation about the sources available and easily accessible? Yes, on YouTube API pages
Filtering
creating sub-corpora: yes
how user-friendly and intuitive is the process: needs some coding skills
Download options: bulk or single downloads: continuous downloads
Download limits: according to quota decided by YouTube for a specific research project
Processing
cloud computing yes
local machines yes
Results
Can you export and share
derived data: yes
examples and snippets: no snippets, written permission required
complete research articles: yes, open access is preferable; YouTube needs to see publication 7 days prior
complete datasets for peer review: no
Continuous access:
datasets: for the duration of the research project; renew datasets every 30 days to ensure updating deleted data
Meta CrowdTangle research program
Who is eligible
By application, university researchers (faculty, PhD students, post-doctoral research fellows)
Topics:
Misinformation
Elections
COVID-19
Racial justice
Well-being
Sources
What is available: access to CrowdTangle tool and CrowdTangle API (which includes Facebook, Instagram and Reddit data)
Which Data: Public posts (excluding posts from individuals) (up to 5000 words), including media (images and videos), metrics, and links. Here is an overview of what data is currently available through CrowdTangle API and CrowdTangle Tool (CrowdTangle tracks data from public content across Facebook Pages and Groups, as well as Verified Profiles and public Instagram accounts. API is needed for large datasets or time series)
How Many: By application, there is no limit officially stated in research program
Which time period: according to application, one research project per application
Is the documentation about the sources available and easily accessible? Yes, on CrowdTangle tool pages
Filtering
creating sub-corpora: yes, the tool allows various filtering
How user-friendly and intuitive is the process:
the tool does not need coding skills, the API does need some coding skills
Download options
bulk or single downloads: continuous downloads
download limits: in bulks of maximum 10 000 posts per request. You can download a maximum of 10,000 Posts in a CSV from a Dashboard. If you export a CSV from the Historical Data tool (accessible via Dashboards), you can get up to 300,000 posts. You can perform a maximum of 100 download requests per day.
Processing
cloud computing yes
local machines yes
Results
Can you export and share
derived data: yes
examples and snippets: yes
complete articles: yes, citing CrowdTangle is required
complete datasets for peer review: no
Continuous access
datasets: for the duration of the research project
TikTok research program
Who is eligible
By application, university researchers from the US only. WIll announce changes soon?
Topics:
various topics
Sources
What is available: access to TikTok API
Which Data: Meta-data on user profiles and content, including metrics, comments, captions and subtitles; key words search data
How Many:
By application, there is no limit officially stated in research program, TikTok assigns the quota
Which time period:
according to application, one research project per application
Is the documentation about the sources available and easily accessible?
No, there are a lot of terms of service right now
Filtering
how user-friendly and intuitive is the process: the API does need some coding skills
Download options
bulk or single downloads: not clear
download limits:not clear
Processing
cloud computing yes
local machines yes
Results
Can you export and share
derived data: yes
examples and snippets: no
complete articles: yes, TikTok needs to see publication 7 days prior
complete datasets for peer review: no
Continuous access
datasets: for the duration of the research project; needs to be updated every 15 days
Summarized information on access in the table: